Evening metadata aficionados,
Jumping in to stoke the fire a bit…
My understanding is that framing is now being considered as an optional set of attributes because AMF is one sneeze away from a “complete” viewing recipe.
Considering AMF is being created to supplement the success and accuracy of a color management system, I’m actually inclined to suggest that framing metadata not be included in the AMF specification. I currently see it as far enough removed from color management to be considered an out-of-scope problem.
I also can’t help doubt the effectiveness of optional metadata in any system. It is a bit lame if filmmakers on-set decide to depend on preserving their framing choices in AMF, but some platform downstream has opted out of interpreting that metadata because it was optional. Additionally, we currently don’t see wide adoption of attributes that are declared as required in specifications like ST 2065-4, so what chance does optional metadata have?
My opinion above aside, I’ve read through the discussion so far in this thread to gather an understanding of the goal with specifying framing metadata. Referencing Chris’s earlier statement:
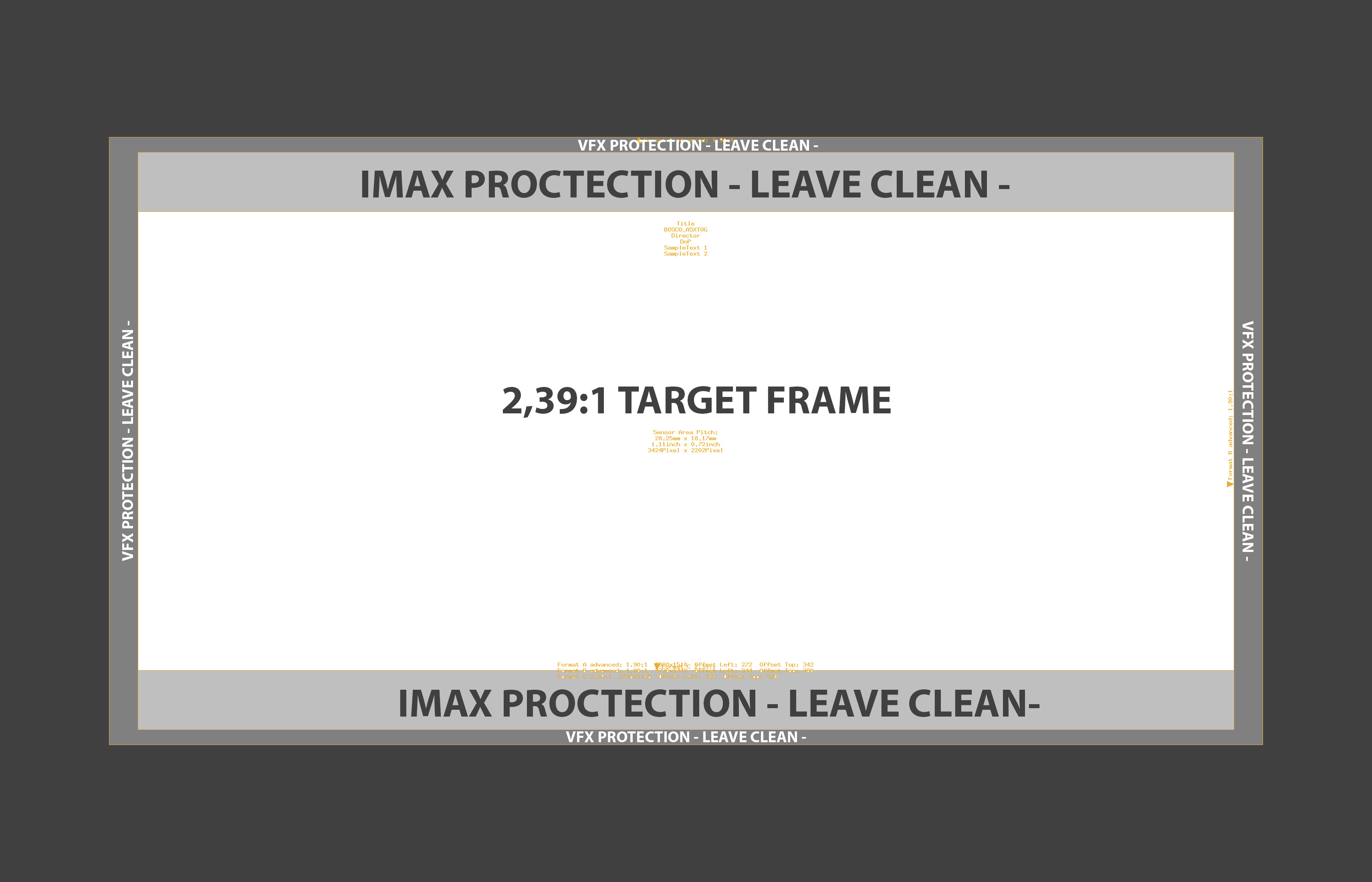
It should be possible to pass a single AMF between all of these places and get the same active image to be fit within the target area of choice within the software.
This looks like the most straightforward goal to me, and a feasible one as well. There is no ambiguity in the original specification that aims to achieve that goal:
<framing>
<inputFrame>4448 3096</inputFrame>
<extractionArea>3840 2160</extractionArea>
<originTopLeft>304 468</originTopLeft>
</framing>
(I can’t help suggesting different names for the above. Why call one Frame and the other Area? I’d suggest inputArea and framingArea. extraction implies performing a hard crop to some.)
Although the above representation is simple, I would describe support for utilizing the extractionArea as a major feature to implement in a given software platform. AMF is per-clip, whereas viewing area / blanking is typically set at the timeline/viewing level in software, and re-mapping different areas per shot may require sophisticated definitions within the software’s configuration (if the application even supports that to begin with).
Some conflicts I would worry about:
- Say you bring in two shots from two different cameras, and one of them has a different aspect ratio for the
extractionArea than the other shot. This is an awkward conflict that a Dailies operator may want to solve by choosing to stop the AMF framing metadata from driving their viewer, because they know what the aspect ratio should be. But that also means the software needs a button to disable reading the AMF’s framing metadata (even per shot!).
- What if shot A has AMF framing metadata, and shot B has no AMF framing metadata to be read? How does the user even know that’s happened, unless shot B’s native aspect ratio is definitely different than the framing of the other shot? The dailies op likely won’t know if the content they’re looking at is definitely framed correctly, unless all of this automation of mapping the framing area is presented by the software in a very transparent way. Possibly the user needs to determine which shots have AMF framing metadata, not mess with those, and then manually intervene with the shots that don’t have that metadata.
- Another feature this may need to support is choosing between multiple framing options. As Francesco has shown through example, you could have more than one frame line live on the camera. This is a pretty sophisticated feature, I think.
I’m also not clear how the AMF is updated for transcodes that alter the resolution. Let’s say I start with this:
<framing>
<inputFrame>5674 3192</inputFrame>
<extractionArea>5390 2695</extractionArea>
<originTopLeft>142 248</originTopLeft>
</framing>
Then I transcode it to EXR and resize the entire image down to 3840x2160 (no cropping). Does the AMF update framing metadata to this?
<framing>
<inputFrame>3840 2160</inputFrame>
<extractionArea>3648 1824</extractionArea>
<originTopLeft>96 168</originTopLeft>
</framing>
The addition of the scaling factors verticalScaling and horizontalScaling, purely for the sake of recognizing images captured with anamorphic lenses, feels a bit awkward to me. Two reasons:
-
These are pre-determining whether the footage should be “stretched” (increase the width by a scaling factor) or “squashed” (decrease the height by a scaling factor). There is value in leaving this flexibility open. You may stretch to avoid having to upsample a de-squeezed image into a larger delivery container. You may squash an image to produce something with a smaller pixel area, in order to save on compute and/or file size.
-
Images captured with anamorphic glass are typically described with a non-zero pixel aspect ratio. pixelAspectRatio is actually a mandatory OpenEXR metadata attribute in ST 2065-4. Is this not enough to communicate non-square pixels? Will optional framing metadata in an AMF be more successful than required metadata in 2065-4? Obviously 2065-4 doesn’t cover the source camera files themselves, but original camera files should really be carrying that sort of info in their own metadata.
Including the concepts behind activeArea and targetArea supports a very different goal. Instead of maintaining the same active image at all stages, this looks to automate some part of the image workflow in Post. This is exponentially more complex than the previously stated goal by Chris.
Some immediate concerns:
- Order of operations now matters. Each given software platform has its own under-the-hood implementation of transforming images (resizing, mapping areas, blanking, and so on). Translating the intended order of the operations successfully from an AMF to each of these systems is a sizable task, especially when we expect that translation to be perfectly consistent across all software platforms.
- This assumes operators know what their
activeArea will be in pre-production. While we would love this to be the task, in reality I reckon that most of the time this is not decided. Who would be responsible for including it after an AMF is initially generated on-set? What software would do that? Is this any easier than doing whatever people are already doing extract these images for VFX pulls, or is it just moving the task from one mechanism to another?
- This makes AMF implementation exponentially more difficult for vendors to support, and therefore much more likely to fail adoption. I would imagine these are major features to add support for.
I hope these concerns don’t come across too pessimistic. Ultimately I think achieving a successful unified color management system is already changing the world, so I am just worried about weighing it down with more objectives that don’t directly benefit color management. If everyone is looking at this as a major selling factor to describe ACES as a system that can preserve the complete viewing recipe, then I’d suggest making it required metadata.