@Alexander_Forsythe,
Thanks for the prompt reply .
Did you have a chance to read my previous post as well, that on on XML namespaces in general?
@Alexander_Forsythe,
Thanks for the prompt reply .
Did you have a chance to read my previous post as well, that on on XML namespaces in general?
Sorry for not getting this feedback in earlier, hopefully this is not too late to be helpful. I have one larger critique of the LMT working space to start with, followed by a bunch of suggestions on rewording different bits of the spec.
6.3.19 aces:lookTransformWorkingSpace
I am struggling to find the original intention and goal of adding this feature, can I request someone highlight that for me? I follow the mechanisms, I’m just not clear on the intended value with providing this flexibility.
I’m pretty divided on this feature. Top pro: leave lin/log conversions up to the applications instead of the LUT. Top con: Interop nightmare web of doom.
I’ll briefly mention TB-2014-010 to get the pedantic problem out of the way. That document lays out a clear definition: “The input to an LMT is always a triplet of ACES RGB relative exposure values; its output is always a new triplet of ACES RGB relative exposure values.”
So, if AMF supports breaking out transformations in order to feed the LMT a non-ACES image, and to receive a non-ACES image from the LMT, it is technically in conflict with the LMT definition. If this is really what is wanted, then TB-2014-010 should be updated along with the release of AMF. I think it is important this is not overlooked, because we should fully expect software vendors to start implementing more LMT features now that they can be exchanged/archived properly with AMF. We should ensure they are implemented against a 100% valid specification.
As for the feature itself, the top advantage, to me, of the currently proposed LMT working space feature is that adjustments applied in non-ACES color spaces do not have to package together all of the ACES to/from conversions into itself. Theoretically, this makes the translation of pre-existing look libraries to LMT libraries easier, because you just have to work out it’s working color space and specify it in the XML. I say theoretically, because in practice I’m sure a vast majority of stashed LUTs output display-referred RGB anyways. Lastly, those lin/log transforms are being trusted to the application rather than the LUT.
The top disadvantage, to me, is how unwieldy this is going to be with software support and interoperability. The current proposal includes that the fromLookTransformWorkingSpace and toLookTransformWorkingSpace are specified as Color Space Conversions transforms. I saw earlier in the thread Alex updated S-2014-002 to allow for user-supplied CSCs. I am wondering how all of this comes together. Many applications have already implemented a lot of these transformations, and they will need to map those functions with these transformIDs, and somehow ensure they accurately reflect them. Does a user-supplied transform need to be uploaded to the ACES github? Who provides reference images for these so every application knows they’ve implemented them properly? What happens when an application receives AMFs referencing a user-supplied LMT working space that it doesn’t support? Does that user need an emergency special build of the software? Or are we back to the same pain we’ve always been in w/o AMF, by manually communicating intentions and digging up the right files to fill out the color recipe?
I’m also concerned this will inevitably lead to different apps performing different to/from transforms, and generate paranoia around relying on AMF workflows. CDLs + LUTs are tedious, but at least you always get the same image out once you’ve stuck them in the correct order.
If we want to look at things like ASC CDL as an inspiration for metadata-driven specifications, maybe it’s worth trying to simplify AMF if we can, and consider removing this to/from transform flexibility. This would leave all of this up to the LMT itself, as expected by the TB-2014-010 document. I’ll end with a quote from the 2017 paper that argues for simplification of ACESclip:
“The ACESclip file format attempts to achieve many things at the same time which is likely another factor slowing down its adoption.”
Out of all the current components of AMF, I would reckon the concept of interpreting and mapping to/from transforms for the LMT working space will be high on the list of slowing down AMF adoption. Again, I’m a bit torn myself on this, but I wanted to unload all of the scrutiny I can before the bell rings.
Grammatical critique:
To preface, I know many industry folks that will be reading this spec whom are not native English speakers. I decided to pick apart most paragraphs and simplify the vocabulary and grammar as much as possible so it is a smoother read. For myself as well!
• Output Transform – on what display was this viewed?
This is completely pedantic, but ODT does not tell us what display was used, it tells it the calibration of the display that was used for viewing. Maybe change this to:
• Output Transform – how was this viewed on a display?
For production, carriage of this information is crucial in order to unambiguously exchange ACES images, looks, and overall creative intent through its various stages (e.g. on-set, dailies, editorial, VFX, finishing).
For archival, storage of this information is crucial in order to form a record of creative intent for historical and remastering purposes.
This is reading awkwardly for me. Also, maybe it’s better to avoid hamstringing the specification by being specific to motion picture production? Suggestion:
To maintain consistent color appearance, transporting this information is crucial. Additionally, this information serves as an unambiguous archive of the creative intent.
An AMF may be associated with a single frame or clip. Additionally, it may remain unassociated with an image, and existing purely as a translation of an ACES viewing pipeline, or creative look, that could be applied to any image.
Attempt to reword for clarity:
An AMF may have a specified association with a single frame or clip. Alternatively, it may exist without any association to an image, and one may apply it to an image. An application of an AMF to an image would translate its viewing pipeline to the target image.
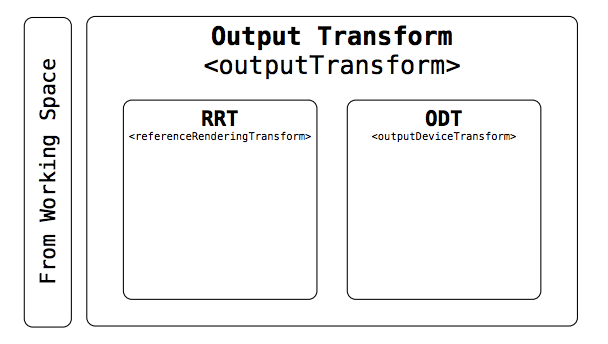
In Figure 1, the element names are extremely squished. Can the RRT + ODT blocks be arranged top down so that these element names can be presented larger?
5 Use Cases
In cases where the looks are stored external to the AMF, the files must be assigned a valid ACES LMT TransformID.
“ACES LMT TransformID”: I’m being pedantic, but it doesn’t help a newbie if they try to search this phrase in the spec and get no other results. The later part of the spec states this as “lookTransform” and “transformID”. Can this sentence at least refer to the relevant section: 6.2.1.6. Or, maybe this sentence can just be removed completely, since it’s a little overkill for the use cases section? Why state LMTs need a transformID, but not IDTs, ODTs, etc…
5.1 Look Development
Developing a creative look before photography can be done to produce a pre-adjusted reference for on-set monitoring. This may happen in pre-production at a post facility, during camera testing, or on-set during production. Typically, this has involved meticulous communication of necessary files and their intention, which may include a viewing transform, CDL grades, or more. The viewing transform, commonly referred to as a “Show LUT,” can vary in naming convention, LUT format, input/output color space, and full/legal range scaling. Exchanging files in this way obfuscates the creative intention of their application, due to lack of metadata or standards surrounding their creation.
I’ve tried to simplify this:
The development of a creative look before the commencement of production is common. Production uses this look to produce a pre-adjusted reference for on-set monitoring. The creative look may be a package of files containing a viewing transform (also known as a “Show LUT”), CDL grades, or more. There are no consistent standards specifying how to produce them, and exchanging them is complex due to lack of metadata.
AMF can store a creative look in order to be shared with a production to automatically recreate the look for on-set monitoring. A common way to produce a creative look in an ACES workflow is the creation of an LMT (Look Modification Transform), which separates the look from the standard ACES transforms. Further, AMF can include references to multiple LMTs, while ensuring they are all applied in the correct order to the image.
Attempt to simplify wording:
AMF contains the ability to completely specify the application of a creative look. This automates the exchange of these files and the recreation of the look when applying the AMF. In an ACES workflow, one specifies the creative look as one or more Look Modification Transforms. AMF can include references to any number of these transforms, and maintains their order of operations.
5.2 On Set
On-set grading software with AMF support can load or generate AMFs based on the viewing pipeline selected and any creative look adjustments done by the DIT or DoP.
Suggestion:
On-set color grading software can load or generate AMFs, allowing the communication of the color adjustments created on set.
5.3 Dailies
The AMF (or collection of AMFs) from on-set should be shared with dailies in order to be applied to the OCF (original camera files) and generate proxies or other dailies deliverables. Methodologies of exchange between on-set and dailies may vary, sometimes being done using ALE or EDLs depending on the workflow preferences of the project.
It is possible, or even likely, that AMFs are updated in the dailies stage. For example, a dailies colorist may choose to balance shots at this stage and update CDLs or LMTs. Another example could be that on-set monitoring was done using an HDR ODT and dailies is generating proxies using an SDR ODT.
Attempt to simplify:
Dailies can apply AMFs from production to the camera files to reproduce the same images seen on set. There is no single method of exchange between production and dailies. AMFs should be agnostic to the given exchange method.
It is possible, or even likely, that one will update AMFs in the dailies stage. For example, a dailies colorist may choose to balance shots at this stage and update CDLs or LMTs. Another example could be that dailies uses a different ODT than the one used in on-set monitoring.
It may be that AMFs are tracked the same way that CDLs and LUTs are tracked today (such as ALE or EDL), until more robust methods exist such as embedding metadata in the various formats used.
I think this sentence “dates” the spec too much. It reads more like an article by talking about the past/present/future. I think the main point here is that defining exchange has been decided to be out-of-scope of this spec, so I think it helps to make that clear. Suggestion:
This specification does not define how one should transport AMFs between stages. Existing exchange formats may reference them, or image files themselves may embed them. One may also transport AMFs independently of any other files.
5.4 VFX
A powerful use case of AMF is the complete and unambiguous communication of the ACES viewing pipelines or ’color recipe’ of shots being sent out for VFX work.
As with on-set, this is commonly done in a bespoke manner with combinations of CDLs and LUTs in various file formats in order for VFX facilities to be able to recreate the look seen in dailies and editorial.
AMFs should be sent alongside outgoing VFX plates and describe how to view the shot along with any creative look that it associated with the shot (CDL or LUT).
Attempt to set this up better and simplify:
The exchange of shots for VFX work requires perfect translation of each shot’s viewing pipeline, or ‘color recipe’. If the images cannot be accurately reproduced from VFX plates, effects will be created with an incorrect reference.
AMF provides a complete and unambiguous translation of ACES viewing pipelines. If they travel with VFX plates, they can describe how to view each plate along with any associated looks.
VFX software should have the ability to read AMF as a template for configuring its internal viewing pipeline. Given the prevalence of OpenColorIO in the VFX software space, it is likely that AMF will inform choices of OCIO configuration in order to replicate the ACES viewing pipeline described in the AMF.
Attempt to simplify:
VFX software should have the ability to read AMF to configure its internal viewing pipeline. Or, AMF will inform the configuration of third party color management software, such as OpenColorIO.
5.5 Finishing
This would give the colorist or artist a starting point which is representative of the creative intent of the filmmakers thus far, at which point they may focus their time on new creative avenues, rather than spending time trying to recreate prior work done.
Attempt to simplify:
AMF can seamlessly provide the colorist a starting point that is consistent with the creative intent of the filmmakers on-set. This removes any necessity to recreate a starting look from scratch.
That is great feedback Joseph!
The ability to use non-ACES working spaces for the Look is certainly one of the most complex aspects of the spec and I agree it will probably be a leading source of interop problems. During the spec drafting working group meetings it seemed like most people felt this was a requirement for the spec, so the question is probably not “should this feature be included?” but rather “how can we design it to work as robustly as possible?” I share your concerns that the current design may prove problematic.
I thought your rewording suggestions were nice improvements. Alex, is it still possible to incorporate these?
Glad to have your participation Joseph!
Doug
I agree with @jmcc that including non-ACES working spaces in AMF may be overkill definitely slowing down the spec’s completition.
The ACESclip requirement VWG had identified such a feature to be, indeed, a requirement for AMF; that is why it is still being discussed.
I was, personally, neutral to that.
However, to clarify the rationale behind lmtWorkingSpace to @jmcc, it should be considered that one may have a pre-existing show LUT working, for example as a ACEScc-to-ACEScc LUT, or "LogC-to-LogC LUT.
Re-using such in an ACES-workflow as a LMT means, otherwise, It is hard to tell these guys to manually convert it into an ACES2065-to-ACES2065 LUT first, before it can be included as the LMT part of an AMF: it makes more sense to define the space(s) it works on in case they’re not implicitly ACES2065-1.
That said, I also agree that, due to the fact that AMF is an ACES component, it could be narrowed down, for now to support only ACES color spaces.
Hey all,
I put together a solution to address the output referred use case where we want to go through the inverse of an output transform or inverse ODT / RRT.
You can take a look at it here :
Basically underneath the <aces:inputTransform> tag you can have a transformID for an IDT, or a series of tags specifying the transformID of an <aces:inverseOutputTransform> or an <aces:inverseOutputDeviceTransform> and <aces:inverseReferenceRenderingTransform>.
You’d use the inverse transforms to convert output referred images to ACES before going forward through the rest of the pipeline as specified in the AMF.
Let me know if this makes sense before I write it up in the spec document.
Thanks for adding that @Alexander_Forsythe.
@ptr would this suffice for your Inv ODT questions here: AMF and transformIds for "special" IDTs and ODTs ?
I want to voice my support for Joe’s grammatical edits to the spec. If there are no objections, I will update the spec with those edits.
I also agree that the non-ACES working spaces adds significant challenges to both implementation and interoperability (as we have already seen). In going back to old recordings from our Requirements group, it sounds like the use case was from a real-world project that used LogC as the LMT working space. Personally, I feel that this workflow could be adapted to utilize an ACEScct working space, and greatly reduce the complexity of the spec. This may deserve its own thread but I wanted to voice my opinion here.
Thanks,
Chris
I just had the chance to take a very brief look today, but the syntax in the new example4.amf looks very good to me. I like that it is explicit that this is not a regular IDT. So yes, that specific issue with the inverse-ODT “IDTs” seems solved very well with that.
I have a question about the latest changes about the WCS definitions that are proposed here: https://github.com/aforsythe/aces-dev/commit/b8497c0af1615ae037635b901df1818336e83d67
Generally limiting the definition of a working color space to the transforms that actually require it – namely the ASC-CDL node – seems like the right way to me in order to limit the use of WCS to necessary use cases, and to further substantiate the intended use of working color spaces in the context of LMTs. It also might help reduce maybe yet unforeseeable consequences for the future of “regular” LMTs, where now ACES 2065-1 (AP0) is always required in order to make them applicable as universally as possible.
I have one question about how to use that in a use case that we currently cover in our software:
In Livegrade (and I guess also in other applications) users have the option also to apply one or more 3D LUTs in the WCS (e.g. ACEScct) before or after the ASC-CDL.*
If we want to recreate such a pipeline (for instance IDT X -> ASC-CDL in WCS Y -> 3DLUT in WCS Y -> RRT -> ODT Z) in other systems, how would we encode that in the proposed AMF variant?
Maybe we are missing a second “legacy” transform node that also requires a WCS definition, namely a “LUT-based transform”. Again you could argue that it is necessary to specify a WCS for that (because applying LUTs in linear doesn’t make much practical sense the same ways as ACS-CDLs). So we might need to introduce a similar mechanism for 1D / 3D LUTs as for ASC-CDLs. Or is this already covered somehow else?
I feel we’re getting very close now, but didn’t nail yet the use cases with externally defined transforms in the role of “LMTs”. With this I mean transforms that are custom-created for certain scenes or productions, and thus need to be defined outside the AMF file (e.g. as the mentioned 3D LUT files, or maybe also as CLF files), and that yet need to be referenced from the AMF file somehow as look transforms in order to be able to recreate that pipeline.
Maybe @Alexander_Forsythe or @CClark can add some clarifying comments. Thank you!
(*) Allowing to apply 3D LUTs in the WCS together with the ASC-CDL has become necessary in order to allow “custom LMTs” (e.g. provided by a post house or dailies facility) to be transported and applied in the format of 3D LUTs – especially as long as we didn’t have CLF or other formats that allow to be applied meaningfully in the scene-linear encoding of ACES 2065-1. Thus providing such “LMTs” as 3D LUTs (to be applied in a certain working color space) has become a practicable way of encoding and applying custom LMTs in such available 3D LUT formats.
Hi Patrick,
You raise a good point! Please also see this thread, which is related to the GitHub commit you cited:
https://community.acescentral.com/t/rethinking-working-spaces-for-amf
My understanding of the current spec is that it does allow your use-case (in your example, applying 3DLUT in WCS Y). But the proposal in that thread is to remove the ability to apply transforms other than a CDL in a working color space (other than ACES2065-1). This is why I wrote in that thread that I was worried that it would remove the ability of AMF to easily support certain use-cases.
The reason that I was not entirely opposed to the proposal is that CLF does support packaging more typical log-space based LUTs into a container that expects and produces ACES2065-1. So that would be one work-around that would allow implementation of the use-case you describe, even with the latest proposed change.
In other words, the working space conversion gets moved from within the AMF implementation into a step of packaging the original LUT from the production into an appropriate ACES2065-1 based LMT as a CLF. We could potentially add something to OCIO to provide that service, if people would find it useful (e.g. using any of the existing ACES CSC transforms and any of the 20+ LUT formats supported by OCIO).
This is an extra step, but as Chris wrote in the proposal, the benefit is that there is no uncertainty about what color space an LMT expects as input and output – it is always ACES2065-1, and thus follows the existing LMT spec from ACES 1.0.
Doug
I think Doug hits the nail on the head here. For a LUT that currently assumes ACEScct (or any other working space) in, there’d need to be a repackaging step that makes the LUT compatible with ACES 2065-1 in/out.
Thanks for clarifying that (sorry that I had not seen that other thread yet).
So to put it differently, the latest proposal of AMF (with the limit of WCS definitions to ASC-CDL) purposely cuts out use cases that use custom 3D-LUTs as look transforms – and relies on the implementation of CLF as a replacement for such 3D LUTs.
I have to admit this is a clean solution, but I agree with Doug Walker that this will have an impact on adoption. While “80%” of use cases (with ASC-CDL only in WCS) might be covered well with AMF then, the “20%” of special cases – where a custom transform is required – cannot be covered with AMF by systems not supporting CLF yet. So the availability of CLF support now becomes a prerequisite for AMF support in systems that want to cover common use cases with AMF comprehensively.
If this becomes the version for ACES 1.2 now, I think these constraints should be clearly communicated as part of the AMF documentation in order to make the requirements clear for implementers.
For instance the ambiguous word “LUT” or vague references to an “external look file” then should be entirely replaced by something like “CLF-based look transform”.
Example (in S_2019_00x_AMF_DRAFT from 2019.12.19):
p7:
AMFs may also embed creative look adjustments as one or more LMTs (using the
<lookTransform>elements). These looks may be in the form of ASC CDL values, or a reference to an external look file or LUT.
→
AMFs may also embed creative look adjustments as one or more LMTs (using the
<lookTransform>elements). These looks may be in the form of ASC CDL values, or a reference to a CLF-based look transform.
I think our intention is to keep the AMF somewhat implementation neutral. It lays out what the processing steps are to get from camera images or ACES images to a screen. The implementation may or may not decide to use LUTs (CLF or others), GPU code, CTL, or others. They may have specific issues that they need to tackle or may choose the concatenate steps. LMTs being the exception I guess …
Currently TB-2014-010 says they are CLF so I guess existing show LUTs would need to be “rewrapped” as ACES to ACES CLFs. This may be something to revisit in ACES 2.0.
I’ll try rewording but “external look file” may be a CLF or something like an EDL with embedded ASC-CDL values.
Hello.
I just read the example AMF from the lates draft and I have three points I’d like to discuss – either today or at another date.
FIRST
One of the CDLs referenced in the AMF sample (approx. line #114) employs the ColorCorrectionRef element:
<cdl:ColorCorrectionRef ref="03345"/>
Actually that is to be used when there is an actual collection of color corrections (in a file with .ccc extension), so that each EDL or ALE file may just reference the name of a specific CDL within those listed in the CCC, without retyping the numeric parameters each time.
Using such CDL feature in AMF means that the AMF is referencing something not within the AMF itself and --ever worse than this-- it is a reference to something that AMF provides no actual mechanism to unambiguously refer to: where could this reference #03345 be ever found externally?
It makes sense to explicitly say in the AMF specs that only individual CDLs may be referenced within AMF.
Or, alternatively, CCC may be allowrd as well in AMF (I suggest under the generic LookTransforms element), so that internal cross-referencing happens, independently in the IDT, LMT, RRT and ODT parts of it.
SECOND
The XML namespacing in the example (a generic xmlns attribute in the root element and no namespace specification in any of the descendant XML elements ) is good as long as AMF is not to be embedded inside something else.
An even better implementation would be to use a namespace tag (actually any namespace tag), like for example amf, specified in a named xmlns:amf attribute in the root element, and use it consistently in any descendant elements. I would recommend that AMF parsers are capable of at least this latter forms – even if most implementations would use the simpler one. I am attaching the two variations here:
amf namespace S_2019_00x_AMF_DRAFT_2019.11.19__full-namespace.amf.xml (increased compatibility if embedded in larger XML)The latter sample is good in case AMF is to be embedded into larger XML files. Using the former sample requires the embedding application to create a namespace and convert the former into the latter before embedding – which embedding application may not be able to do.
This may seema a neglectible problem now, but if you think about it many existing applications already use XML-based project files: Foundry Nuke, Autodesk Flame, FilmLight Baselight, R&S Clipster, Colorfront, Apple FinalCut ProX, etc. They may ultimately benefit from having the opportunity to streamline the embedding of AMF into their products.
This would eventually facilitate adoption of AMF by manufacturers of software that is already XML-based based.
THIRD
As agreed during one of the recent VWG calls, I am attaching a few variations of the sample AMF, with a few stressing of XML syntax in a ZIP file.
The files are all valid XML files, therefore the any application honoring AMF should be capable of parsing all of them. If not, the parsers may not be complete.
I would strongly suggest adding some soft of reference AMFs so that manufacturers can stress their AMF parsing capability.
Those who are long time in the business know that just saying XML is not good… somethimes XML files from “obscure” implementations need to be post-processed by whitespce / end-of-line / syntax-check tools before they become totally interoperable among different implementations that use incomplete writers to generate data files, and/or incomplete parsers to read them.
In the end:
@walter.arrighetti I think you’re working off of old files. This is has been reflected in the sample files since November 25, 2019. The examples in the RC1 version of the specification., the aces-dev repo at RC1, and the [latest sample files post-RC1 feedback latest sample files continue to include the explicit name spacing.
I completely agree but I think this an issue for the implementation group to deal with rather than including the spec. I could add a details about required line endings to the spec if people want.
Hi Alex. The file is S_2019_00x_AMF_DRAFT_2019.11.19.amf.xml this one.
It is taken from the 2019.11.19 spec draft sample
But I can see now it was from an old spec: I don’t think the CDL ref exists any longer in the four samples in the GitHub repo.
Thanks Walter,
The latest complete draft spec is posted at the top of this thread. There’s also a link to the working copy on overleaf that is a work in progress but incorporates changes such those to the LMT working spaces that we’ve been discussing.
I think your point about the cdl:ColorCorrectionRef may be valid even though it isn’t in the latest examples. The type for the cdl:ColorCorrectionRef attribute ref is AnyURI. Would it be useful to specify the pattern for the ref URI?
Hi Alex.
The ColorCorrectionRef element should be either avoided in CDLs used inside AMF, or it should be defined how to reference external CDLs (the same way AMF may reference an external LUT, or an external piece of footave gia clipID)… which I’d rather avoid.
In my opinion, CDLs inside AMF should be fully described as Slope/Offeset/Power/Staturation 10-tuples. But if ColorCorrectionRef is to be allowed as well, then the specs shouls clearly state how to reference.
Possible, alternative solutions are:
ref is allowed to be a UUID which is an identifier pointing to another part of the AMF, where that CDL’s slope/offset/power/saturation values are defined. This pars with my earlier (2019) proposal for hosting a repository of transforms inside and AMF file, which the transforms used in the IDT, LMT, RRT, ODT parts of the AMF file all refer to.
ref is allowed to be a UUID to CDL embedded somewhere else by means of default XML extensibility features. For example, it points to the id attribute of an XML element containing both a SOPNode and a SatNode.
ref is allowed to be a filename or an online resource (in this case a AnyURI may stay). In that case AMF may reference external CDLs (like it does with referring to external LUTs or external footage via clipID). In which case, however, it should be stated clearly that applications “validating” AMFs should check whether the externally-referenced CDLs are available as well.
Choice #1 is also good in the case of AMFs with looong pipeline histories. where most of the pipelines in the history share many color transforms: having one “vault” with all the used the transforms helps keeping the size of the AMF file small.
Walter,
The AMF currently supports CDLs specified inside the AMF itself using <cdl:SOPNode> and <cdl:SATNode> or <cdl:ColorCorrectionRef> as a means to reference a CDL in an external file. See details in the schema.